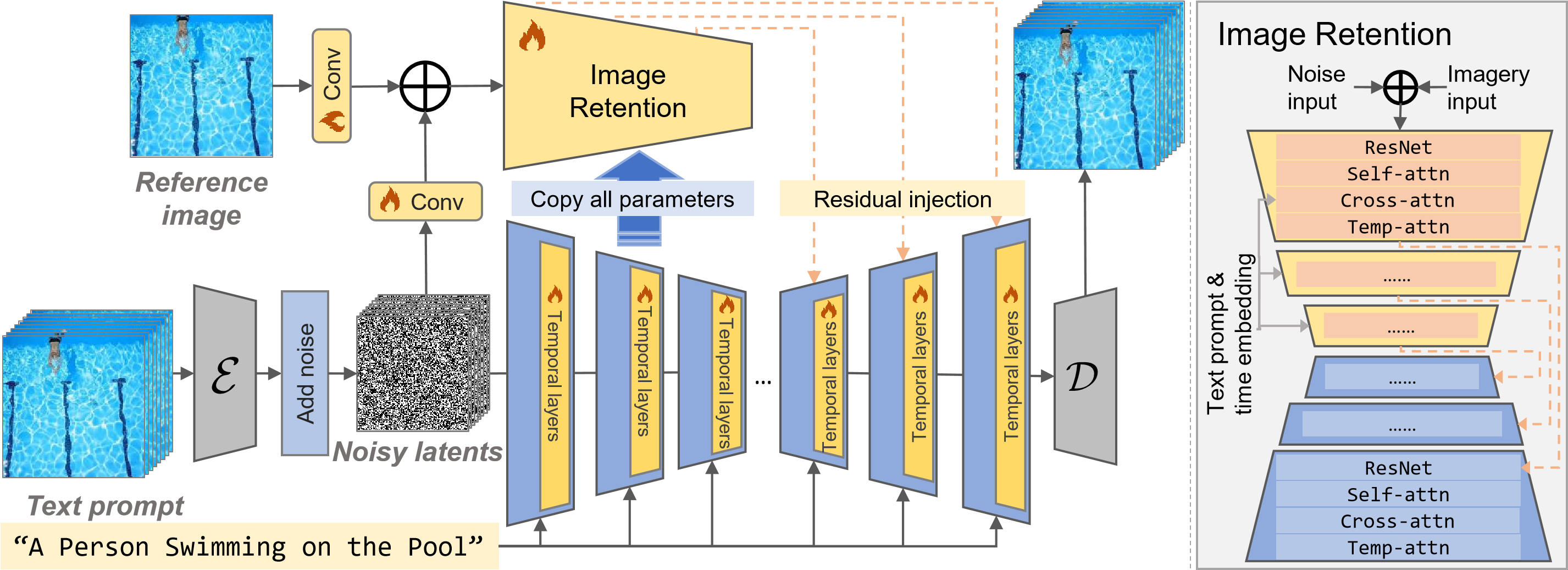
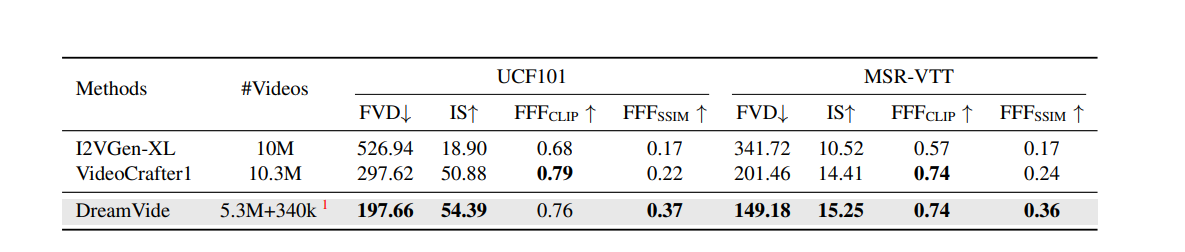
Image-to-video generation, which aims to generate a video starting from a given reference image, has drawn great attention. Existing methods try to extend pre-trained text-guided image diffusion models to image-guided video generation models. Nevertheless, these methods often result in either low fidelity or flickering over time due to their limitation to shallow image guidance and poor temporal consistency. To tackle these problems, we propose a high-fidelity image-to-video generation method by devising a frame retention branch based on a pre-trained video diffusion model, named DreamVideo. Instead of integrating the reference image into the diffusion process at a semantic level, our DreamVideo perceives the reference image via convolution layers and concatenates the features with the noisy latents as model input. By this means, the details of the reference image can be preserved to the greatest extent. In addition, by incorporating double-condition classifier-free guidance, a single image can be directed to videos of different actions by providing varying prompt texts. This has significant implications for controllable video generation and holds broad application prospects. We conduct comprehensive experiments on the public dataset, and both quantitative and qualitative results indicate that our method outperforms the state-of-the-art method. Especially for fidelity, our model has a powerful image retention ability and delivers the best results in UCF101 compared to other image-to-video models to our best knowledge. Also, precise control can be achieved by giving different text prompts. Further details and comprehensive results of our model will be presented here.